
Модель геометрической структуры синсета
Аннотация
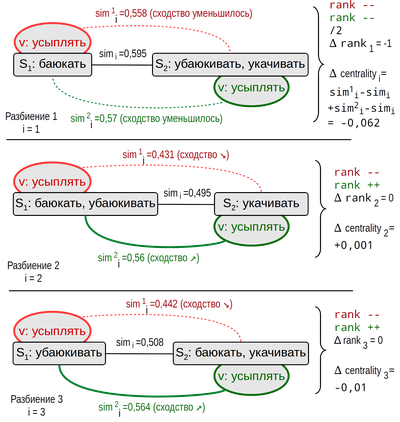
В статье поставлен вопрос формализации понятия синонимии. На основе векторного представления слов в работе предлагается геометрический подход для математического моделирования наборов синонимов (синсетов). Определен такой вычислимый атрибут синсетов как "внутренность синсета" (IntS). Введены понятия "ранг" и "центральность" слов в синсете, позволяющие определить более значимые, "центральные" слова в синсете. Для ранга и центральности даны математическая формулировка и предложена процедура их вычисления. Для вычислений использованы нейронные модели (Skip-gram, CBOW), созданные программой Т. Миколова word2vec. На примере синсетов Русского Викисловаря построены IntS по нейронным моделям корпусов проекта RusVectores. Результаты, полученные по двум корпусам (Национальный корпус русского языка и новостной корпус), в значительной степени совпадают. Это говорит о некоторой универсальности предлагаемой математической модели.
Ключевые слова
Полный текст:
PDFЛитература
Александрова З. Е. Словарь синонимов руского языка. М.: Русский язык, 2001. 586 с.
Баранов В. И., Стечкин Б. С. Экстремальные комбинаторные задачи и их приложения. М.: Физматлит, ISBN: 5-9221-0493-4, 2004. 238 с.
Каушинис Т. В., Кириллов А. Н., Коржицкий Н. И., Крижановский А. А., Пилинович А. В, Сихонина И. А., Спиркова А. М., Старкова В. Г., Степкина Т. В., Ткач С. С., Чиркова Ю. В., Чухарев А. Л., Шорец Д. С., Янкевич Д. Ю., Ярышкина Е. А. Обзор методов и алгоритмов разрешения лексической многозначности: Введение. Серия Математическое моделирование и информационные технологии, Труды Карельского научного центра Российской академии наук, 2015. С. 69–98. doi: 10.17076/mat135.URL: http://journals.krc.karelia.ru/index.php/mathem/article/view/135 (дата обращения: 9.05.2016)
References in English
Baroni M., Dinu G., Kruszewski G. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. In Proceedings of the ACL ’14, 2014. P. 238–247. URL: http://anthology.aclweb.org/P/P14/P14-1023.pdf (accessed: 9.05.2016)
Goldberg Y., Levy O. word2vec explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722, 2014. P. 1–5.
Huang E. H., Socher R., Manning C. D., Ng A. Y. Improving word representations via global context and multiple word prototypes. In Proceedings of the ACL ’12, Jeju Island, Korea, 2012. P. 873–882. URL: http://dl.acm.org/
citation.cfm?id=2390524.2390645 (accessed: 9.05.2016)
Krizhanovsky A. A., Smirnov A. V. An approach to automated construction of a general-purpose lexical ontology based on Wiktionary. Journal of Computer and Systems Sciences International, 2013. No2. P. 215–225. doi:10.1134/S1064230713020068. URL:http://scipeople.com/publication/113533/ (accessed: 9.05.2016)
Kutuzov A., Kuzmenko E. Comparing neural lexical models of a classic national corpus and a web corpus: the case for Russian. Computational Linguistics and Intelligent Text Processing, 2015. P. 47–58. doi: 10.1007/978-3-319-18111-0_4. URL: https://www.academia.edu/11754162/Comparing_neural_lexical_models_of_a_classic_national_corpus_and_a_web_corpus_the_case_for_Russian
(accessed:9.05.2016)
Kutuzov A., Andreev I. Texts in, meaning out: neural language models in semantic similarity task for Russian. arXiv preprint arXiv:1504.08183, 2015. URL: http://www.dialog-21.ru/digests/dialog2015/materials/pdf/KutuzovAAndreevI.pdf (accessed: 9.05.2016)
Levy O., Goldberg Y., Dagan I. Improving distributional similarity with lessons learned from word embeddings. Transactions of the Association for Computational Linguistics, 2015. Vol. 3. P. 211-225.
Mahadevan S., Chandar S. Reasoning about linguistic regularities in word embeddings using matrix manifolds. arXiv preprint arXiv:1507.07636. 2015. P. 1–9.
Mikolov T., Kombrink S., Burget L., Cernocky J., Khudanpur S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference
on Acoustics Speech and Signal Processing (ICASSP), 2011. doi: 10.1109/icassp.2011.5947611. URL: http://dx.doi.org/10.1109/icassp.2011.5947611 (accessed: 9.05.2016)
Mikolov T., Zweig G. Context dependent recurrent neural network language model. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), 2012.
doi: 10.1109/slt.2012.6424228. URL: http://dx.doi.org/10.1109/slt.2012.6424228 (accessed: 9.05.2016)
Mikolov T., Chen K., Corrado G., Dean J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013. URL: http://arxiv.org/abs/1301.3781
(accessed: 9.05.2016)
Princeton University. What is WordNet? URL: http://wordnet.princeton.edu (accessed: 9.05.2016)
Rehurek R., Sojka P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges
for NLP Frameworks, Valletta, Malta: University of Malta, 2010. P. 45–50. URL: http://is.muni.cz/publication/884893/en (accessed: 9.05.2016)
RusVectores: distributional semantic models for Russian. URL: http://ling.go.mail.ru/dsm/en/ (accessed: 9.05.2016)
Sidorov G., Gelbukh A., Gomez-Adorno H., Pinto D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Computacion y Sistemas, 2014. Vol. 18, No3. P. 491-504. URL: http://www.scielo.org.mx/pdf/cys/v18n3/v18n3a7.pdf (accessed: 9.05.2016)
DOI: http://dx.doi.org/10.17076/mat394
Ссылки
- » —
© Труды КарНЦ РАН, 2014-2019